개요
스레드 생성 과정은 간략하게 아래와 같은 과정이 이루어진다.
메모리 할당 -> 시스템 콜(커널 모드 전환) -> 운영체제에서 스레드 생성 -> 운영체제 스케쥴러 관리 -> 작업이 완료되면 스레드 종료
스레드 생성 과정은 너무 무겁다.
또한 서버의 자원은 한정되어 있기에, 스레드를 무한하게 생성할 수도 없다.
스레드 풀을 이용하면 스레드들을 미리 만들어서 보관해놓고 생성 과정을 일부 생략하여 작업을 빠르게 진행시킬 수 있으며, 최대 스레드 수를 설정하여 서버의 자원을 초과하지 않도록 할 수 있다.
Executor 프레임워크
자바에서는 Executor 프레임워크를 통해 스레드 풀 관리를 간단하고 효율적으로 처리할 수 있다.
public interface ExecutorService extends Executor, AutoCloseable {
<T> Future<T> submit(Callable<T> task);
@Override
default void close(){...}
...
}ExecutorService 인터페이스를 주로 사용하며, 기본 구현체는 ThreadPoolExecutor이다.
ThreadPoolExecutor 구조 및 동작

ThreadPoolExecutor를 이루는 요소는 크게 BlockingQueue와 스레드 풀로 이루어져 있다.
- BlockingQueue -> 작업을 보관하며, 생산자 소비자 문제를 해결
- 스레드 풀 -> 미리 생성된 스레드를 직접 관리하며, BlockingQueue에 작업을 받아서 처리
생산자 소비자 문제란?
임계 영역(Queue) 내의 락을 가지고 무한 대기하는 문제
- ex 1) 작업이 비어있는 Queue 내의 작업을 소비하기 위해, 소비자는 임계 영역의 락을 획득하고 작업이 들어오기까지 대기
-> 소비자가 락을 갖고있으므로, 생산자는 작업을 추가할 수 없음
-> 생산자와 소비자 모두 교착상태
- ex 2) 작업이 가득차 있는 Queue내의 작업을 추가하기 위해, 생산자는 임계 영역의 락을 획득하고 자리가 생길때까지 대기
-> 생산자가 락을 갖고있으므로, 소비자는 작업을 소비할 수 없음
-> 생산자와 소비자 모두 교착상태
BlockingQueue 스레드 차단을 통해 멀티 스레드 환경에서 생산자 소비자 문제를 해결하기 위한 특별한 큐
ThreadPoolExecutor 생성 및 스레드 풀 관리 전략
ExecutorService es = new ThreadPoolExecutor(
2, 4, 3000, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(2)
);
생성자를 통해 스레드 풀을 커스텀하게 생성할 수 있으며, 위 생성자의 매개변수의 의미는 다음과 같다.
- 기본 스레드 2개
- 최대 스레드 4개
- 최대 스레드 생존 대기 시간 3초
- 작업을 보관할 크기가 2인 BlockingQueue
기본적으로 스레드 풀은 기본 스레드만을 사용한다. 기본 스레드 2개가 모두 사용 중이라면, BlockingQueue에 작업이 보관된다.
만약 BlockingQueue에도 대기 중인 작업이 가득찼다면? 비로소 최대 스레드만큼 2개의 초과 스레드가 마저 생성이 된다.
작업이 완료된 초과 스레드는 3초 동안 대기하게 된다면 제거된다.
고정 스레드 풀 전략
ExecutorService es = new ThreadPoolExecutor(
3, 3, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()
);스레드 풀에 기본 스레드만큼 생성하고, 초과 스레드는 생성하지 않는 전략이다.
스레드 수가 고정되어 있기에 컴퓨팅 리소스가 어느정도 예측 가능하지만, 트래픽이 늘어날 경우 문제가 발생할 수 있다.
Executors.newFixedThreadPool(3)Executors 인터페이스를 통해 동일한 스레드 풀을 간략하게 생성할 수 있다.
캐시 스레드 풀 전략
ExecutorService es = new ThreadPoolExecutor(
0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()
);모든 작업이 대기하지 않고, 작업의 수 만큼 스레드가 생성되는 전략이다.
시스템 자원을 최대로 사용할 수 있지만, 갑작스럽게 요청이 증가할 경우 많은 스레드로 인해 서버가 다운될 수 있다.
Executors.newCachedThreadPool()Executors 인터페이스를 통해 동일한 스레드 풀을 간략하게 생성할 수 있다.
ThreadPoolExecutor 주요 메서드
void execute(Runnable)Runnable 작업을 제출한다. 반환값은 없다.
Future<T> submit(Callable<T> task)Callable 작업을 제출하고 결과를 반환한다.
Callable과 Future는 별도의 글로 정리할 예정이다.
void shutdown()새로운 작업을 받지 않고 이미 제출된 작업을 모두 완료한 후 스레드 풀을 종료한다.
List<Runnable> shutdownNow()새로운 작업을 받지 않고, 실행 중인 작업을 중단하고 대기 중인 작업을 반환한다.
boolean isTerminated()shutdown(), shutdownNow() 호출 이후, 모든 작업이 완료되었는지 확인한다.
void close()shutdown()과 동일하며, 자바 19 이후부터 지원한다.
try (ExecutorService e = Executors.newCachedThreadPool()) {
// submit or execute many tasks with e ...
}AutoClosable 인터페이스를 구현하고 있기에 try-resource문을 통해 자동으로 자원을 종료시킬 수 있다.
try-resource 블록을 빠져나오거나 close() 메서드와 같이 자원을 닫는 시점이 된다면, 메인 스레드는 블로킹되고 제출된 모든 작업 스레드의 결과를 기다린다.
기존에 Thread.join() 메서드의 기능을 대신한다고 볼 수 있다.
Executor 예외 정책
BlockingQueue도 가득차고 초과 스레드도 더 이상 할당할 수 없다면, 다양한 정책을 통하여 작업을 거절할 수 있다.
AbortPolicy
ExecutorService es = new ThreadPoolExecutor(
1, 1, 0, TimeUnit.SECONDS, new SynchronousQueue<>(),
//AbortPolicy
new ThreadPoolExecutor.AbortPolicy()
);작업이 거절되면, RejectedExecutionException을 던진다.
DiscardPolicy
ExecutorService executor = new ThreadPoolExecutor(
1, 1, 0, TimeUnit.SECONDS, new SynchronousQueue<>(),
//DiscardPolicy
new ThreadPoolExecutor.DiscardPolicy()
);
거절된 작업을 무시하고 아무런 예외도 발생시키지 않는다.
CallerRunsPolicy
ExecutorService executor = new ThreadPoolExecutor(
1, 1, 0, TimeUnit.SECONDS, new SynchronousQueue<>(),
//CallerRunsPolicy
new ThreadPoolExecutor.CallerRunsPolicy()
);호출한 스레드가 직접 작업을 수행한다.
ThreadPoolExecutor 사용 예시
class MyTask implements Runnable {
private final int taskSequence;
public MyTask(int sequence) {
this.taskSequence = sequence;
}
@Override
public void run() {
try {
//외부 API 호출로 인한 I/O 블로킹
Thread.sleep(1000L);
System.out.println("작업 완료 : " + taskSequence);
} catch (InterruptedException e) {
System.out.println("작업 실패");
}
}
}여기 외부 API 호출로 인한 I/O 블로킹으로 1초간 스레드가 블로킹되는 작업이 있다.
long startTime = System.currentTimeMillis();
//작업을 동기적으로 진행
for (int i = 0; i < 10; i++) {
MyTask myTask = new MyTask(i);
myTask.run();
}
long endTime = System.currentTimeMillis();
System.out.println("모든 작업 완료 시간 : " + (endTime - startTime));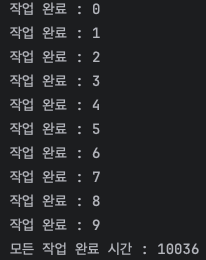
해당 작업들을 동기적으로 진행할 경우 1초 * 10개 = 총 10초의 작업이 소요된다.
long startTime = System.currentTimeMillis();
// 스레드 풀을 통해 작업들을 비동기적으로 진행
try(ExecutorService es = Executors.newFixedThreadPool(100)) {
for (int i = 0; i < 100; i++) {
es.submit(new MyTask(i));
}
}
long endTime = System.currentTimeMillis();
System.out.println("모든 작업 완료 시간 : " + (endTime - startTime));
작업들을 스레드 풀에 할당하여 진행할 경우, 작업들이 비동기적으로 진행된다. 1초 만에 10개의 작업이 모두 완료된 것을 볼 수 있다.
ThreadPoolExecutor 특징
1. BlockingQueue에 작업을 스레드 풀에 넣고 스레드가 스레드 풀의 작업을 꺼내서 실행하는 product-consumer 구조이다.
2. 각 스레드는 BlockingQueue에 들어온 작업을 순차적으로 처리한다. 동시성 처리에 적합하다.
3. 스레드 수를 많이 만들어도 상관이 없기에, 작업 특성은 대기 시간이 많은 I/O 바운드 작업에 적합하다.
(커스텀하게 설정한 많은 스레드들이 모두 CPU 바운드 작업으로 돌게되면 CPU의 과부하가 클 것이다.)
'Language > Java' 카테고리의 다른 글
| [Java] Virtual Thread 부셔보기 (0) | 2026.02.04 |
|---|---|
| [Java] Callable과 Future & CompletableFuture (0) | 2026.02.01 |
| [Java] ReentrantLock을 통한 스레드 동기화 (0) | 2026.01.02 |
| [Java] 자바 스레드 생명 주기와 메모리 가시성 (0) | 2025.12.30 |
| [Java] Stream Collector, Downstream Collector (0) | 2025.12.26 |